GPT3 nezvlĂĄdĂĄ Äeskou gramatiku a pravopis - nÄkolik pĹĂkladĹŻ, na kterĂ˝ch si jazykovĂ˝ model mÄnĂcĂ svÄt vylĂĄme zuby

GTP3 je skvÄlĂ˝ nĂĄstroj, kterĂ˝ nabĂzĂ ĹĄirokou paletu vyuĹžitĂ a kterĂĄ zcela jistÄ promÄnĂ (a jiĹž promÄĹuje) svÄt tak, jak jej znĂĄme. ZĂĄroveĹ vĹĄak mĂĄ pĹirozenÄ svĂŠ limity, kterĂŠ jsme si ukĂĄzali hned na nÄkolika pĹĂkladech - aĹĽ jiĹž ĹĄlo o generovĂĄnĂ vymyĹĄlenĂ˝ch vĂ˝sledkĹŻ vÄdy a vĂ˝zkumu s odkazy na fiktivnĂ zdroje Äi nezvlĂĄdnutĂŠ matematickĂŠ Ăşlohy. SvĂŠ rezervy mĂĄ samozĹejmÄ i v dalĹĄĂch oblastech - a k jednĂŠ takovĂŠ patĹĂ takĂŠ ÄeskĂ˝ jazyk - konkrĂŠtnÄ ÄeskĂĄ gramatika a pravopis. A prĂĄvÄ na toto tĂŠma se zamÄĹĂm v dneĹĄnĂm textu.
Co GPT3 jde? PrĂĄce s existujĂcĂm textem
GTP3 velmi dobĹe zvlĂĄdĂĄ prĂĄci s obsahem textu, tj. tzv. ÄtenĂ s porozumÄnĂm. PĹestoĹže funguje âmimozemskyâ (tj. nepouĹžĂvĂĄ zpĹŻsoby pĹemýťlenĂ a uvaĹžovĂĄnĂ, kterĂŠ jsou typickĂŠ pro ÄlovÄka, a pracuje pĹedevĹĄĂm s pravdÄpodobnostmi, predikcemi, odhadem a matematickĂ˝mi modely), mĹŻĹžeme zjednoduĹĄenÄ ĹĂci, Ĺže svĂ˝m osobitĂ˝m matematickĂ˝m zpĹŻsobem chĂĄpe obsah textu, vĂ, jak je text vystavÄn, dokĂĄĹže zachytit dĹŻleĹžitĂŠ myĹĄlenky, dokĂĄĹže ovÄĹit, zda je naĹĄe tvrzenĂ v souladu s obsahem textu, dokĂĄĹže vygenerovat klĂÄovĂĄ slova apod.
V Äem selhĂĄvĂĄ? V aplikaci nÄkterĂ˝ch gramatickĂ˝ch a pravopisnĂ˝ch pravidel
ÄeĹĄtina je pomÄrnÄ sloĹžitĂ˝ jazyk, coĹž potvrdĂ celĂĄ Ĺada cizincĹŻ, kteĹĂ se z nÄjakĂŠho dĹŻvodu zaÄali ÄeĹĄtinu uÄit a ovlĂĄdali jiĹž pĹedtĂm jinĂ˝ svÄtovĂ˝ jazyk. Dalo se tedy pĹedpoklĂĄdat, Ĺže zvlĂĄdnout Äeskou gramatiku bude oĹĂĹĄkem i pro neurĂĄlnĂ sĂtÄ. A skuteÄnÄ, v tĂŠto oblasti neurĂĄlnĂ sĂĹĽ chybuje. NestaÄĂ totiĹž pouze zanalyzovat Äi vygenerovat text, ale pochopit a pouĹžĂt sprĂĄvnÄ konkrĂŠtnĂ pravidlo. PojÄme se tedy podĂvat na to, co GPT3 nezvlĂĄdĂĄ.
A. Rozpoznat typicky Äeskou âĹživotnostâ nezvlĂĄdĂĄ
Na nÄkolika pĹĂkladech jsem si otestoval, Ĺže aktuĂĄlnĂ verze modelu neumĂ urÄit gramatickou kategorii Ĺživotnost, kterĂĄ je typickĂĄ pro muĹžskĂ˝ rod. ChybnÄ je jiĹž definice, se kterou model pracuje, logicky jsou pak chybnĂŠ i odpovÄdi.
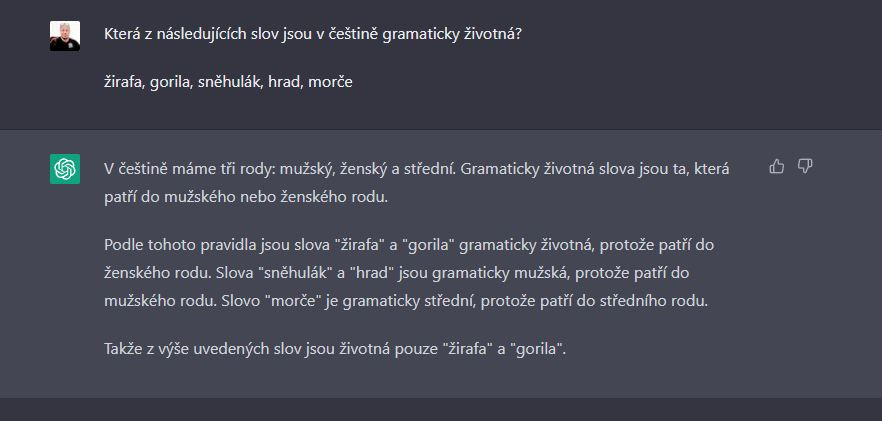
B. OhebnĂĄ a neohebnĂĄ slova jsou oĹĂĹĄek
OhebnĂĄ a neohebnĂĄ slova jsou pro GPT3 oĹĂĹĄek - model opÄt pracuje s chybnou definicĂ, kdy k neohebnĂ˝m slovnĂm druhĹŻm neĹadĂ pĹĂslovce, spojky, ÄĂĄstice ani citoslovce, navĂc k neohebnĂ˝m ĹadĂ ânÄkterĂŠ zĂĄjmenaâ. Proto takĂŠ selhĂĄvĂĄ v situaci, kdy mĂĄ pracovat s pĹĂslovci. SchvĂĄlnÄ jsem pouĹžil pĹĂklad, ve kterĂŠm je jednoznaÄnĂŠ pĹĂslovce vÄera, ve kterĂŠm nedochĂĄzĂ k zĂĄmÄnÄ s podstatnĂ˝m jmĂŠnem (jako napĹ. ve slovÄ rĂĄno). Podle GPT3 je vÄera âohebnĂĄ pĹĂslovceâ.
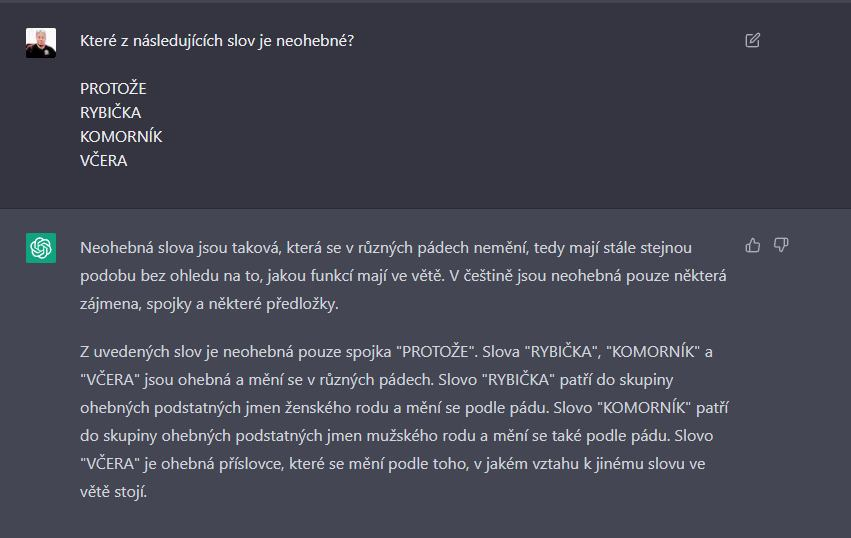
A abych nezapomnÄl, pĹedloĹžky za neohebnĂŠ slovnĂ druhy nepovaĹžuje vĹŻbec. Je vĹŻbec zajĂmavĂŠ, Ĺže slovo vÄera povaĹžuje za ohebnĂŠ a slovo dnes za neohebnĂŠ.
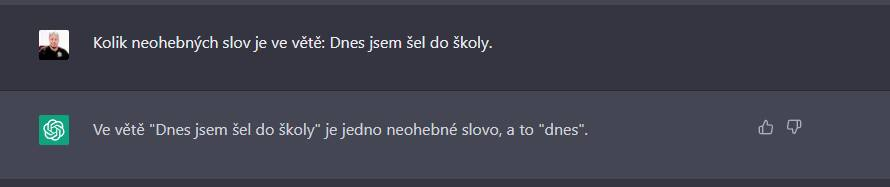
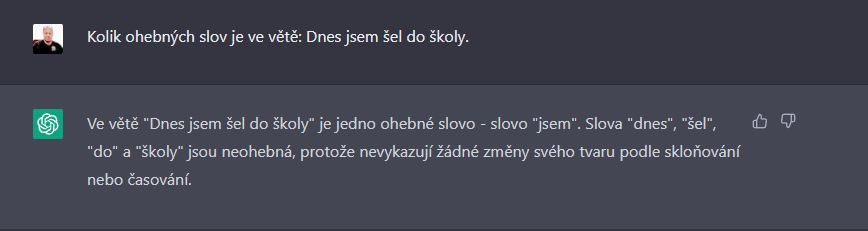
Jakmile se zeptĂĄm ve stejnĂŠ vÄtÄ pro zmÄnu na ohebnĂĄ slova, opÄt selĹže, tentokrĂĄt pro zmÄnu pĹedloĹžku za neohebnĂ˝ slovnĂ druh povaĹžuje. A pro zmÄnu je pro nÄj nynĂ neohebnĂŠ i sloveso ĹĄel.
C. UrÄovĂĄnĂ nevyjĂĄdĹenĂ˝ch vÄtnĂ˝ch ÄlenĹŻ
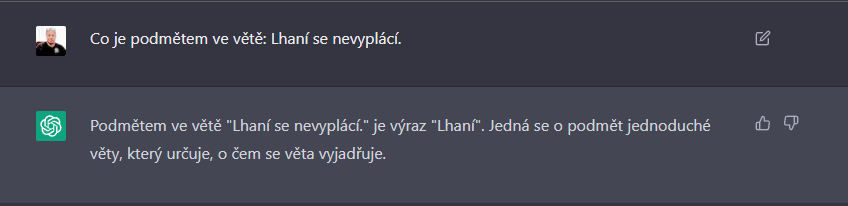
GPT3 velmi dobĹe zvlĂĄdĂĄ urÄovĂĄnĂ jednoduchĂ˝ch vÄtnĂ˝ch ÄlenĹŻ, kterĂŠ jsou ve vÄtÄ explicitnÄ uvedeny, neumĂ vĹĄak pracovat s vÄtnĂ˝mi Äleny, kterĂŠ se ve vÄtÄ pĹĂmo nenachĂĄzejĂ - viz napĹ. nevyjĂĄdĹenĂ˝ podmÄt. Jakmile mĂĄ vÄta nevyjĂĄdĹenĂ˝ podmÄt (ONI), podle GPT3 vÄta podmÄt nemĂĄ a jde podle nÄj o bezpodmÄtnou vÄtu.
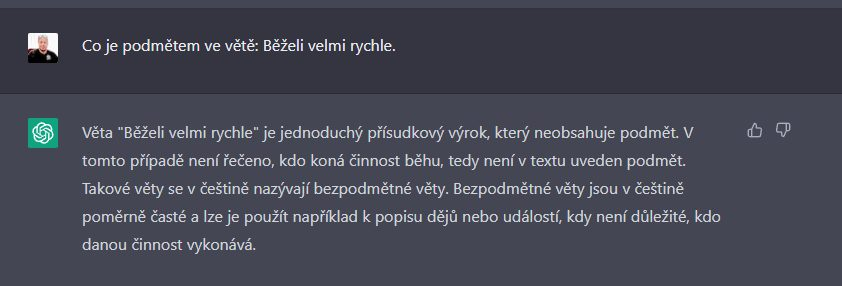
D. Sloveso v infinitivu jako podmÄt GPT3 neodhalĂ
Pokud se ve vÄtÄ v pozici podmÄtu objevĂ sloveso v infinitivu (coĹž je v ÄeĹĄtinÄ zcela bÄĹžnĂŠ), GPT3 opÄt situaci chybnÄ vyhodnotĂ jako bezpodmÄtnou vÄtu.
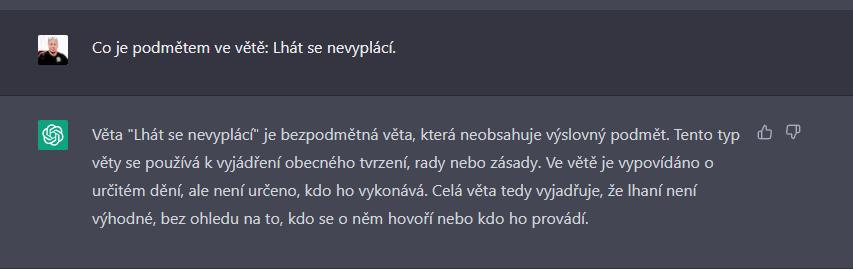
Se slovem âlhanĂâ jiĹž problĂŠm nemĂĄ a odpovĂdĂĄ sprĂĄvnÄ:
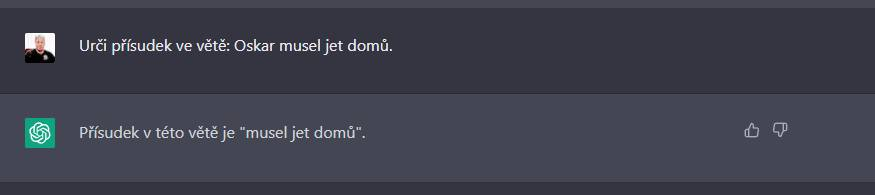
E. SloĹžitÄjĹĄĂ pĹĂsudek s pĹĂsloveÄnĂ˝m urÄenĂm? Pro GPT3 problĂŠm
GPT3 mĂĄ problĂŠm takĂŠ s pĹĂsudkem, na kterĂ˝ jsou navĂĄzĂĄny dalĹĄĂ vÄtnĂŠ Äleny - ty povaĹžuje za jeho souÄĂĄst. V tomto pĹĂpadÄ povaĹžuje pĹĂsloveÄnĂŠ urÄenĂ mĂsta (domĹŻ) za souÄĂĄst pĹĂsudku.
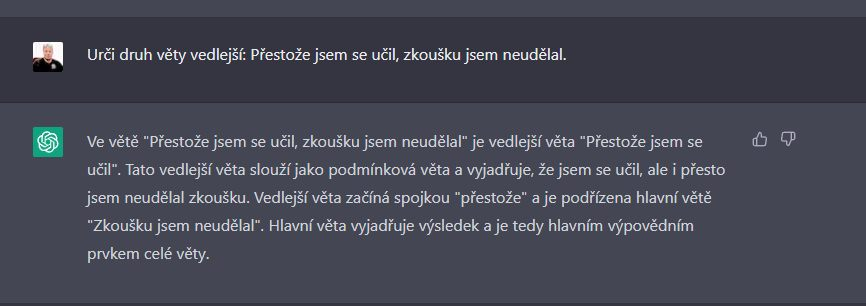
F. VedlejĹĄĂ vÄty - problĂŠmy s podmĂnkami a pĹĂpustkami
Pokud zadĂĄte GPT3 rozpoznat pĹĂpustkovou vÄtu (tj. dÄj probÄhl, i kdyĹž mu nÄco brĂĄnilo), zpravidla si s nĂ neporadĂ a urÄĂ ji jako podmĂnkovou. Pracuje s chybnĂ˝mi definicemi, chyby dÄlĂĄ u dalĹĄĂ typĹŻ vÄt vedlejĹĄĂch.
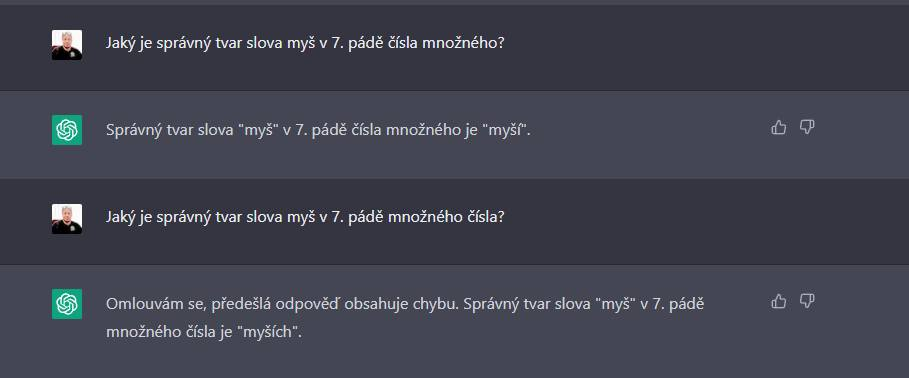
G. SprĂĄvnĂŠ tvary slov? NÄkdy ano, nÄkdy ne
Otestoval jsem si takĂŠ, zda GPT3 zvlĂĄdne tvoĹit sprĂĄvnĂŠ tvary slov. Zkusil jsem to na typickĂŠm ÄeskĂŠm pĹĂkladu MYĹ . SchvĂĄlnÄ, kolik z vĂĄs vĂ, jakĂ˝ je sprĂĄvnĂ˝ tvar tohoto slova v 7. pĂĄdÄ mnoĹžnĂŠho ÄĂsla? Pokud netuĹĄĂte, kliknÄte sem. KaĹždopĂĄdnÄ GPT3 se domnĂvĂĄ, Ĺže je to MYĹ I, pozdÄji opravil svĂŠ tvrzenĂ na MYĹ ĂCH, oboje je ale ĹĄpatnÄ.
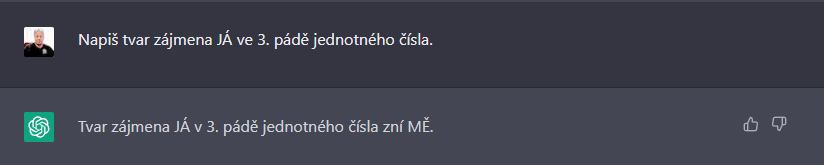
Co myslĂte, zvlĂĄdne GPT3 sprĂĄvnÄ urÄit, ve kterĂ˝ch tvarech zĂĄjmena JĂ se pĂĹĄe MÄ a MNÄ? Ne, nezvlĂĄdne⌠Tvar zĂĄjmena JĂ v 3. pĂĄdÄ jednotnĂŠho ÄĂsla podle GPT3 = MÄ (sprĂĄvnÄ ovĹĄem MNÄ).
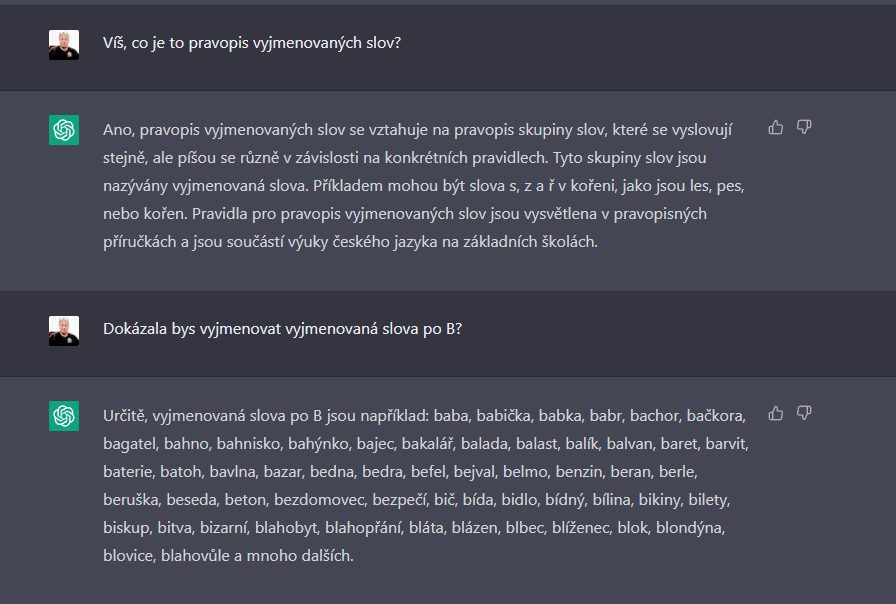
H. VyjmenovanĂĄ slova? NeumĂâŚ
SamozĹejmÄ mÄ zajĂmalo, zda GPT3 zvlĂĄdĂĄ vyjmenovanĂĄ slova, tj. to, co se Şåci uÄĂ nÄkdy od 3. tĹĂdy zĂĄkladnĂ ĹĄkoly. NejdĹĂve jsem se zeptal, zdali GPT3 vĂ, co je to pravopis vyjmenovanĂ˝ch slov, potĂŠ jsem se pokusil chytrou sĂĹĽ pĹesvÄdÄit, aby mi vyjmenovala vyjmenovanĂĄ slova po B. Tak pĹĂĄtelĂŠ: baba, babiÄka, babka, bachor, baÄkora, bagatel a bahno, to jsou podle GPT3 vyjmenovanĂĄ slova.

DidaktickĂĄ vyuĹžitelnost
AĹž budete svĂŠ Şåky Äi studenty uÄit pracovat s neurĂĄlnĂmi sĂtÄmi, urÄitÄ s nimi vyzkouĹĄejte podobnĂĄ zadĂĄnĂ, u kterĂ˝ch vĂte, Ĺže je umÄlĂĄ inteligence vyĹeĹĄĂ chybnÄ. PotĂŠ nechte Şåky odhalit, v Äem udÄlal stroj chybu (napĹ. v definici, v algoritmu, nepochopenĂ otĂĄzky apod.), a opravit chybnĂŠ ĹeĹĄenĂ, kterĂŠ nĂĄm GPT3 nabĂzĂ. PĹĂpadnÄ se pokuste opravit i pĹŻvodnĂ poĹžadavek (prompt) tak, aby byly vĂ˝sledky sprĂĄvnĂŠ. S Şåky se mĹŻĹžete takĂŠ prostĹednictvĂm dalĹĄĂch promptĹŻ pokusit neurĂĄlnĂ sĂti vysvÄtlit, v Äem pĹesnÄ udÄlala chybu. SchvĂĄlnÄ, dokĂĄĹžete ji pĹesvÄdÄit, aby chybu uznala?
To vĹĄe povede k tomu, Ĺže se Şåci nauÄĂ o generovanĂ˝ch vĂ˝sledcĂch zdravÄ pochybovat a nebudou GPT3 automaticky pouĹžĂvat jako zdroj ovÄĹenĂ˝ch a stoprocentnÄ pravdivĂ˝ch informacĂ, coĹž pro aktuĂĄlnĂ verzi skuteÄnÄ neplatĂ. Žåci se zĂĄroveĹ nauÄĂ klĂĄst otĂĄzky tak, aby neurĂĄlnĂ sĂĹĽ poskytovala co nejpĹesnÄjĹĄĂ vĂ˝sledky.
A to je pro dneĹĄek vĹĄe, na zĂĄvÄr jeĹĄtÄ pĂĄr zajĂmavĂ˝ch odkazĹŻ.
DalĹĄĂ doporuÄenĂŠ texty od externĂch autorĹŻ:
ChatGPT a jeho vyuĹžitĂ v praxi (Spajk.cz)
UmÄlĂĄ inteligence a zadĂĄvĂĄnĂ ĂşkolĹŻ (Manena.info)
TIP#2359: MĹŻĹžete pouĹžĂt #AI (#ChatGPT) pro psanĂ ÄlĂĄnkĹŻ? Jak zadĂĄvat AI co mĂĄ dÄlat? (365 tipĹŻ)
Pokud se vĂĄm dneĹĄnĂ text lĂbil, mĹŻĹžete mi koupit virtuĂĄlnĂ kafe. :)
ZobrazenĂ: 5528Hledat
Fotky




































































Sidebar menu
NejÄtenÄjĹĄĂ za poslednĂ rok
- Zkouťky pod lupou: Výkon vs. dojem
- Je na Äase vrĂĄtit hodinĂĄm literĂĄrnĂ vĂ˝chovy smysl
- JakĂŠ kompetence budou muset uÄitelĂŠ ovlĂĄdnout v ĂŠĹe umÄlĂŠ inteligence?
- Jak mĹŻĹže umÄlĂĄ inteligence pomoci pĹi tvorbÄ vĂ˝zkumnĂ˝ch dotaznĂkĹŻ
- Argot nenĂ jen jazyk zlodÄjĹŻ a dalĹĄĂch deklasovanĂ˝ch skupin